Open Source Metadata extractor tool (National Library of NZ)
About
The Metadata Extraction Tool was developed by the National Library of New Zealand (Te Puna Mātauranga o Aotearoa) to programmatically extract preservation metadata from a range of file formats like PDF documents, image files, sound files Microsoft office documents, and many others. It is now available as open-source software from http://meta-extractor.sf.net/. The Tool builds on the Library’s work on digital preservation, and its logical preservation metadata schema. It is designed to: o Automatically extract preservation-related metadata from digital files. o Output that metadata in XML formats for use in preservation activities. The Tool was designed for preservation processes and activities, but can be used to for other tasks, such as the extraction of metadata for resource discovery.
Capabilities
The Tool has both a Microsoft Windows interface and a UNIX command line interface. This enables work to be automated through batch processing or processed on an individual basis as required.
How the Tool works
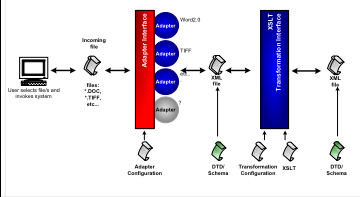
The Metadata Extraction Tool is based on a library of adapters. Each adapter knows how to recognise and extract metadata from a different type of file. Adapters can handle dependencies within and between objects of varying levels of complexity, ranging from single, simple objects like TIFF files through to complex web sites or databases.
Architecture
Extracting preservation metadata is a two-stage process. In the first phase each incoming file is processed by the adapters until one of the adapters recognises the file type. That adapter extracts data from the header fields of the file and generates an Extensible Markup Language (XML) file. In the second phase an Extensible Stylesheet Language (XSL) transformation converts the internal XML file into an XML file in a useful format. The Tool currently outputs the XML file using the NLNZ preservation metadata data model schema.
Preservation constraints
The Tool operates under these constraints: o It must not change the files it processes. o It must process many thousands of files. o It must be consistent. o It must process simple objects (single files) and complex objects (many dependant files). The Tool opens all files as read-only, ensuring the integrity of original files. It usually only reads header information so the extraction process is fast. Consistency is vital because decisions about preservation will be based upon the extracted metadata.
